
A common problem in using Python to gather data via APIs is pagination. Most APIs have a limit on how much data they are willing to send you in a single API call. So they break the data into pages. In this blog post, I’ll go through an example of handling API pagination in Python.
First steps
In this example, we will be downloading a data set from the National Vulnerability Database. This is a relatively large data set, with data on approximately 212,000 vulnerabilities in common pieces of computer software at the time of this writing.
Most paginating APIs work in a similar fashion, so you can adapt this methodology to whatever paginating API you need to work with. The advantage here is your tax dollars paid for this API. That means you are free to use it to learn as much as you like.
Like most modern APIs, the National Vulnerability Database outputs JSON and accepts parameters saying which page and how large to make the page.
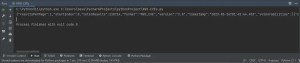
Let’s toss together some minimal Python code to retrieve the one short page of data from the API and print it. That’s my usual first step. From there I can usually figure out what to do next. The pagination information is usually either near the beginning or the end.
import requests
import pandas as pd
import json
# query the NVD CVE API
url = 'https://services.nvd.nist.gov/rest/json/cves/2.0'
response = requests.get(url, params={'startIndex': 0, 'resultsPerPage': 1}) # startIndex and resultsPerPage are the parameters
print(response.text)
And here’s the first few lines of the response, which tells us what we need:
{"resultsPerPage":1,"startIndex":0,"totalResults":210714,"format":"NVD_CVE","version":"2.0","timestamp":"2023-03-26T01:45:44.453"
Handling the API pagination
I’ve seen some APIs tell you the number of pages. But it’s more common for them to tell you the total number of objects and the number of objects per page, like this one does. This is trickier to handle. It’s also more flexible. If new data materializes while you are in the process of retrieving it, it means you will still get the data. I think the trade-off is worth it.
In this case, we know where the page size and objects are stored. So we can use a simple while loop with a count to iterate through the pages, concatenate them, and then write the data out to Excel.
import requests
import pandas as pd
import json
from flatten_json import flatten
nvddf = pd.DataFrame() # initialize the dataframe
# download NVD CVE data and populate the dataframe
start = 0
limit = 1
url = 'https://services.nvd.nist.gov/rest/json/cves/2.0'
while start <= limit:
response = requests.get(url, params={'startIndex': start}) # we will use the default resultsPerPage
data = json.loads(response.text)
print('startIndex: ', data['startIndex'])
start += 1
limit = data['totalResults'] / data['resultsPerPage']
# flatten the json, then add to the dataframe
nvd = pd.json_normalize(data)
nvddf = pd.concat([nvddf, nvd])
# write output file to current directory as an Excel spreadsheet
writer = pd.ExcelWriter("NVD-CVEs.xlsx", engine='xlsxwriter')
nvddf.to_excel(writer, sheet_name='CVE data', index=False)
This is a simple example but easy to expand upon. One thing you’ll probably want to add is error handling, which I sometimes do with recursion. It’s not as complicated as it sounds.
If you work in the field of vulnerability management, this data may even prove useful to you and you may want to build on this. If you work in another field, you can use this as a framework to gather data from a paginating API that is useful to you.
David Farquhar is a computer security professional, entrepreneur, and author. He has written professionally about computers since 1991, so he was writing about retro computers when they were still new. He has been working in IT professionally since 1994 and has specialized in vulnerability management since 2013. He holds Security+ and CISSP certifications. Today he blogs five times a week, mostly about retro computers and retro gaming covering the time period from 1975 to 2000.